Dies ist eine alte Version des Dokuments!
LU01c - DBs Einsetzen & Relationale Datenbanken
Datenbanken einsetzen
Datenbanken haben sich als fester Bestandteil von IT-Landschaften etabliert. Sie spielen eine wesentliche Rolle, wo immer Software-Applikationen zum Einsatz kommen und auf eine gemeinsame, integrierte Datenbasis zugreifen.
Vorteile beim Einsatz von Datenbanken
- Eine Datenbank ermöglicht die dauerhafte, zentrale Speicherung von Daten und kann diese eigenständig verwalten. Das Speichern und Abfragen erfolgt über eine Skriptsprache wie SQL oder einer herstellerspezifischen Abwandlung (z.B. T-SQL von Microsoft).
- Der Einsatz von Datenbanken verhindert Redundanzen (mehrfache Speicherung gleicher Informationen) und Inkonsistenzen (Probleme bei der Aktualisierung mehrfach gespeicherter Datensätze). Zudem wird die Programm-Daten-Abhängigkeit aufgelöst, da alle Programme eine zentrale Datenbasis verwenden.
- DBMS bieten eine Vielzahl von Datenanalyse-Methoden zur Auswertung von Informationen. Die SQL-Skriptsprache stellt Funktionen zur Berechnung, Aggregation und Sortierung der Daten zur Verfügung.
- Datenbankmanagementsysteme (DBMS) sind abfrageoptimiert und können Daten in einem Bruchteil der Zeit auslesen, die andere Dateiformate (z.B. Excel, CSV) benötigen.
Relationale Datenbanken (Relational Databases)
Relationale Datenbanksysteme (RDBMS, *Relational Database Management Systems*) existieren seit den 1980er Jahren und haben sich seitdem zum De-facto-Standard für die Verwaltung strukturierter Daten entwickelt. Sie sind die am weitesten verbreiteten Datenbanksysteme weltweit. Relationale Datenbanken ermöglichen eine strukturierte Speicherung von Daten, die in Tabellen (tables), Spalten (columns) und Zeilen (rows) organisiert sind. Diese Struktur hilft dabei, Daten effizient zu verwalten und zu durchsuchen.
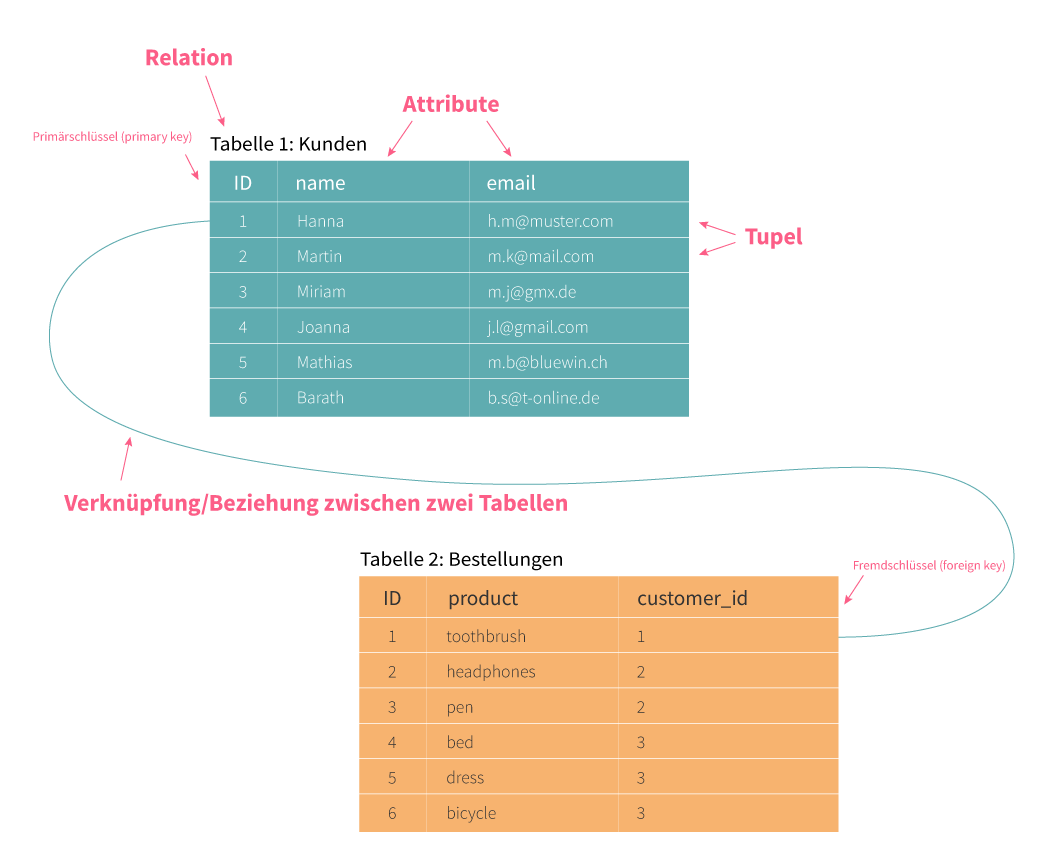
Ein zentrales Konzept relationaler Datenbanken ist die Relation (relation), ein mathematischer Begriff, der als Grundlage für das Modell von Daten dient. Jede Tabelle in einer relationalen Datenbank stellt eine Relation dar, wobei jede Zeile dieser Tabelle als Tupel (tuple) bezeichnet wird. Eine Zeile (Tuple) repräsentiert dabei ein Datensatz. Die Spalten einer Tabelle sind durch Attribute (attributes) definiert, und die Spaltenüberschriften repräsentieren die Attributnamen (attribute names). Ein einzelner Eintrag in einer Zeile und einer Spalte wird als Attributwert (attribute value) bezeichnet.
Die erste Zeile einer Tabelle gibt die Struktur der Tabelle an und definiert die Anzahl und die Benennung der Spalten. Die Verknüpfungen zwischen den Tabellen ermöglichen es, Beziehungen zwischen den gespeicherten Entitäten (entities) zu modellieren und so Datenredundanzen zu vermeiden. So können beispielsweise mehrere Tabellen miteinander in Beziehung gesetzt werden, um komplexe Datenstrukturen abzubilden und die Datenkonsistenz zu gewährleisten.
Stellen Sie sich eine Tabelle, die Kundendaten speichert vor. Jede Zeile der Tabelle repräsentiert dabei einen Kunden. Jede Spalte gibt bestimmte Informationen über den Kunden an, wie z.B. den Namen und die Email-Adresse. In einer Tabelle für Bestellungen könnte eine Zeile eine einzelne Bestellung darstellen, und die Spalten könnten Informationen wie die Bestellnummer oder das Bestelldatum enthalten.
- Zeile = Tupel (tuple): Eine Zeile enthält alle Informationen zu einem bestimmten Datensatz (z.B. ein Kunde oder eine Bestellung).
- Spalte = Attribut (attribute): Die Spalten der Tabelle beschreiben Merkmale des Kunden (z.B. „Name“ oder „Email“).
Was bedeutet Relation?
Der Begriff Relation ist der mathematische Ursprung für die Struktur von Tabellen. Eine Relation (relation) ist einfach eine Tabelle, die eine bestimmte Art von Daten speichert (z.B. Kunden, Bestellungen). Der Name „relational“ kommt daher, dass wir Beziehungen (Relations) zwischen verschiedenen Tabellen herstellen können.
Wie sind Tabellen miteinander verbunden?
Ein wichtiger Bestandteil relationaler Datenbanken ist, dass Tabellen miteinander verknüpft werden können. Diese Verknüpfung erfolgt über Primär- und Fremdschlüssel (primary and foreign keys). Ein Fremdschlüssel ist ein Verweis von einer Tabelle auf eine andere. Zum Beispiel:
- In einer Kundentabelle könnte jede Zeile eine Kundennummer enthalten.
- In einer Bestellungstabelle könnte es eine Spalte geben, die die Kundennummer enthält. Dieser Verweis stellt eine Verbindung zwischen den beiden Tabellen her, weil wir so wissen, welcher Kunde welche Bestellung gemacht hat.
Bekannte relationale Datenbanksysteme (RDBMS)
- MySQL
- MariaDB
- PostgreSQL
- SQLite
- IBM DB2
- Oracle Database
- Microsoft SQL Server
MySQL, MariaDB, PostgreSQL und SQLite sind frei nutzbare, Open-Source-Datenbanksysteme. Besonders MySQL (und MariaDB, das ein Fork von MySQL ist) sind weit verbreitet und kommen häufig in Webanwendungen zum Einsatz. Beispielsweise nutzt WordPress MySQL, was bedeutet, dass über 40% aller Websites weltweit ihre Daten über MySQL oder MariaDB verwalten.
SQL
Relationale Datenbanken nutzen die Structured Query Language (SQL), um Daten abzufragen (query), zu modifizieren (manipulate), zu löschen (delete) und zu verwalten. SQL ist eine standardisierte Programmiersprache, die speziell für die Verwaltung relationaler Daten entwickelt wurde. Dabei haben verschiedene Datenbankanbieter oft eigene Erweiterungen oder Dialekte von SQL entwickelt, wie z.B. T-SQL (Transact-SQL) von Microsoft oder PL/SQL (Procedural Language/SQL) von Oracle. Mehr dazu auf der nächsten Seite.
Video: Relationale und NoSQL-Datenbanken
![]() Dieses Video erklärt den Aufbau von relationalen Datenbanken. 1)
Dieses Video erklärt den Aufbau von relationalen Datenbanken. 1)
Nutzen Sie die automatische Untertitel-Übersetzung von YouTube, wenn die englische Sprache Verständnisschwierigkeiten bereitet.
NoSQL-Datenbanken zur Speicherung grosser/hochfrequenter Datenmengen
NoSQL-Datenbanken sind eine jüngere Technologie und werden vor allem verwendet, wenn Daten in einer unstrukturierten oder wenig strukturierten Form abgelegt werden müssen. NoSQL-Datenbanken wurden besonders im Zusammenhang mit dem Big Data Hype populär. Sie ermöglichen es, grosse Datenmengen schnell zu speichern und auszuwerten, wobei Konsistenz und Aktualität der Daten weniger im Fokus stehen. Die Hauptaufgabe dieser Datenbanken ist es, grosse und hochfrequente Daten effizient zu verarbeiten.
Bekannte NoSQL-Datenbanksysteme
- MongoDB
- Redis
- Apache Cassandra
Vergleich von Relationalen und NoSQL-Datenbanken
- Relationale Datenbanken wurden ursprünglich aufgrund von Speicherknappheit und teurer Speichermedien zum Standard. Mit der Entwicklung effizienterer Speichertechnologien sind diese Probleme heute nicht mehr so gravierend und Speicherplatz ist relativ günstig.
- Relationale Datenbanken sind aufgrund von Integritätsprüfungen und Normalisierungen nicht für die schnelle Speicherung grosser Datenmengen geeignet. Für diese Aufgaben bieten NoSQL-Datenbanken eine bessere Lösung, da sie auf eine schnelle Verarbeitung ohne hohe Integritätsanforderungen optimiert sind.
- Relationale Datenbanken sind nach wie vor unverzichtbar, wenn es auf Genauigkeit, Integrität, Aktualität und Nachvollziehbarkeit ankommt. Typische Anwendungsfälle sind Transaktionssysteme wie Webshops, Online-Banking und Buchungssysteme.